

Meta’s PyTorch team has introduced Monarch, a new distributed programming framework designed to extend the simplicity of PyTorch to entire clusters. Monarch combines a Python-based front end for easy integration with existing libraries, including PyTorch, with a Rust-based back end to ensure high performance, scalability, and robustness. The framework aims to simplify distributed computing, making it accessible to developers familiar with standard single-machine programming.
Announced on October 22, Monarch is built on scalable actor messaging, which allows users to program distributed systems as if they were running on a single machine. By abstracting the complexities of cluster management, Monarch handles parallelization, distribution, and vectorization behind the scenes. While the framework is still experimental, installation instructions are available on meta-pytorch.org for developers eager to explore its capabilities.
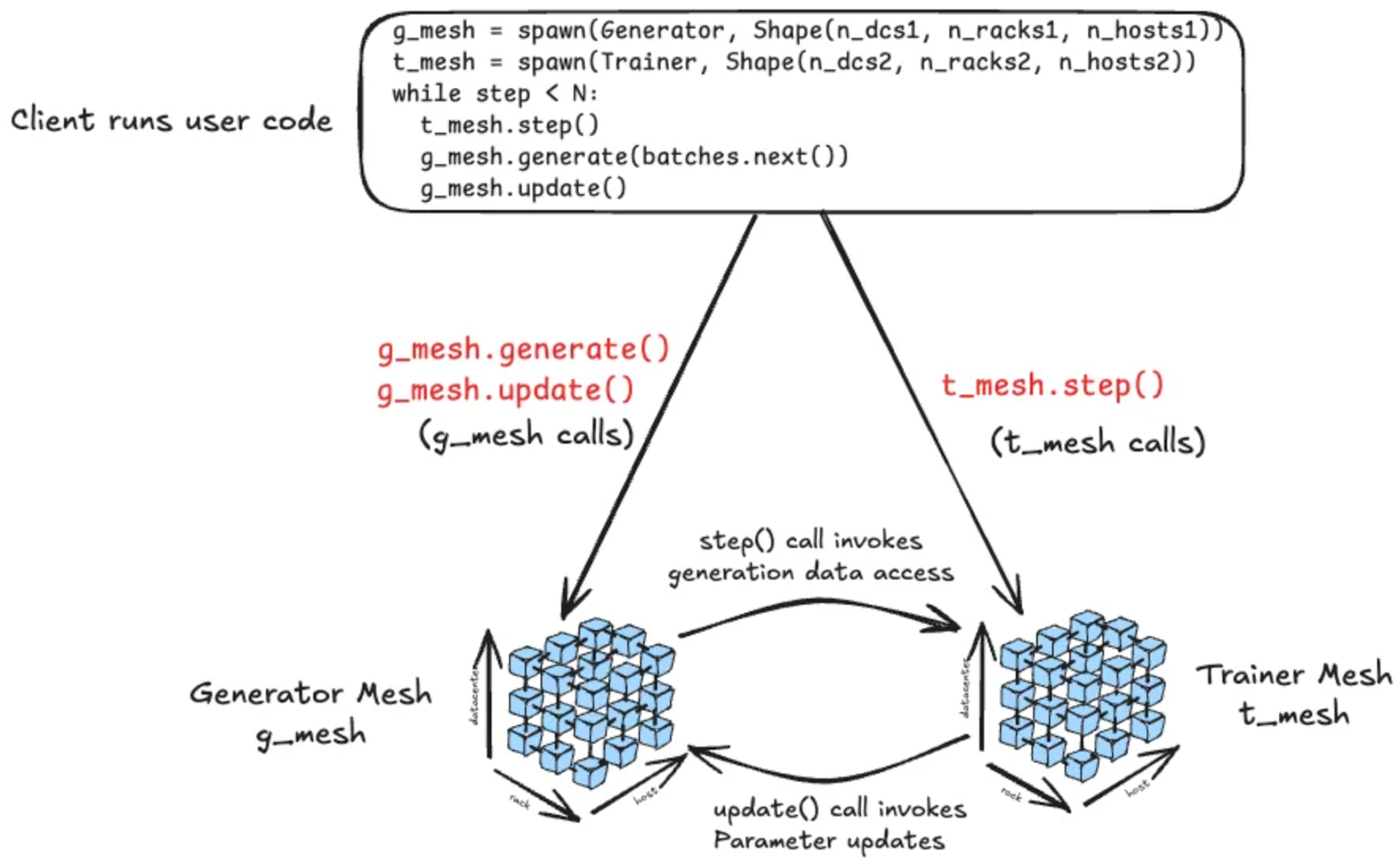
Monarch structures processes, actors, and hosts into a multidimensional mesh that can be manipulated directly through intuitive APIs. Users can operate on entire meshes or subsets of them, with Monarch automatically managing the underlying distribution. The system is designed to fail fast in the event of errors, but developers can later add custom fault handling to recover from failures, providing a balance between simplicity and control.
One of Monarch’s standout features is the separation of control plane messaging from data plane transfers, enabling efficient GPU-to-GPU memory operations across clusters. Tensors are sharded across GPUs, allowing operations to appear local while executing across thousands of devices. Monarch handles the coordination and communication required for these distributed operations, making large-scale machine learning workflows more manageable. The PyTorch team cautions that Monarch is still in an early stage, so users should expect incomplete features, potential bugs, and evolving APIs.