

Community Pushes Kubernetes Forward with Native AI Inference Tools
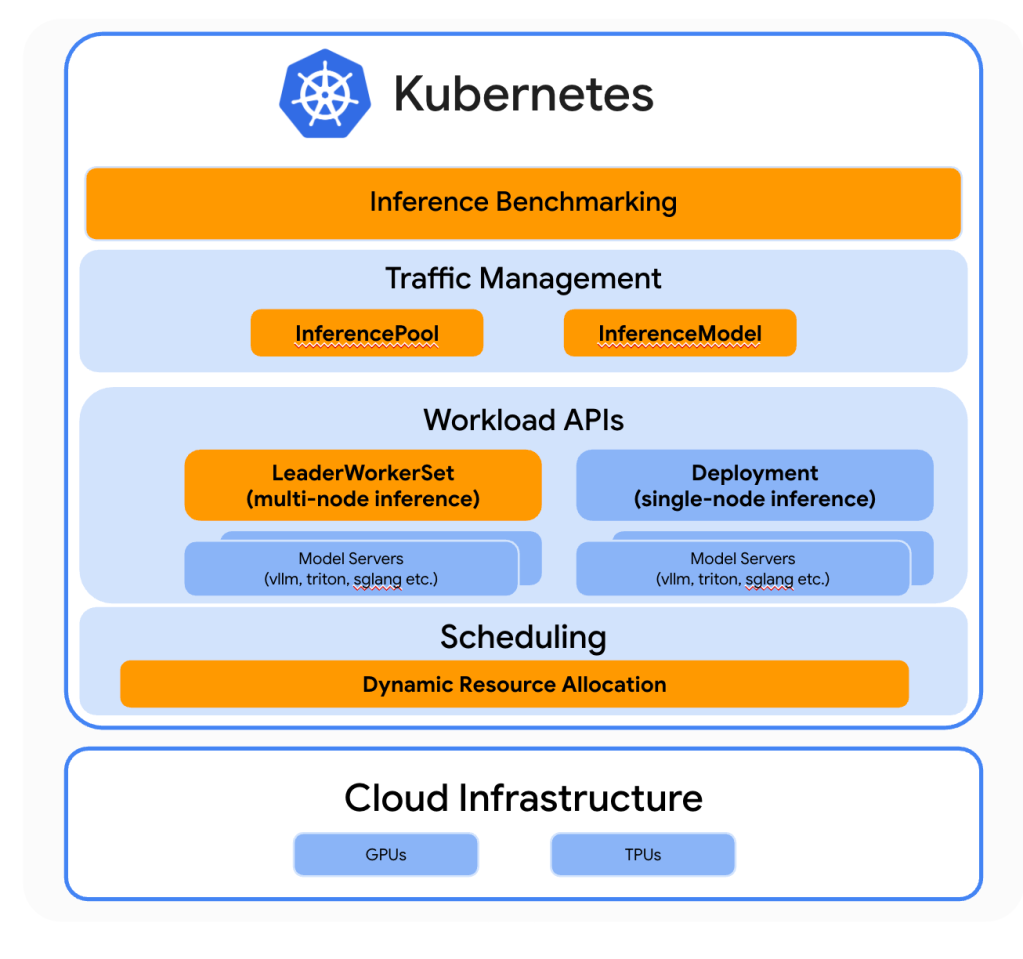
Kubernetes has long been the go-to platform for deploying cloud-native applications and microservices, thanks to its extensive community support and powerful orchestration capabilities. But the surge of generative AI has exposed new challenges that go beyond traditional container management. Large language models, specialized hardware, and intensive request/response patterns demand a system that is not only scalable but also AI-aware, capable of intelligently handling inference workloads.
To address these challenges, Google Cloud, ByteDance, and Red Hat collaborated on enhancements directly within the Kubernetes open-source project. Their goal is to equip Kubernetes with the native capabilities needed to efficiently manage AI inference, turning it into a platform optimized for the high demands of generative AI. These improvements reflect a community-driven approach, ensuring that the ecosystem benefits from shared expertise and open standards.
Among the key advancements is the Inference Perf project, which benchmarks and qualifies accelerators for AI workloads. This ensures that developers and operators can reliably measure performance across hardware options and select the right resources for their generative AI tasks. Additionally, the Gateway API Inference extension enables LLM-aware routing, allowing scale-out architectures to intelligently distribute inference requests while balancing load across multiple endpoints.
Another critical innovation is Dynamic Resource Allocation (DRA) for AI accelerators, combined with the vLLM library for LLM inference and serving. These tools allow Kubernetes to dynamically schedule workloads across heterogeneous hardware while providing efficient, high-throughput inference. Together, these advancements create a more robust, scalable, and AI-focused Kubernetes platform, paving the way for the broader adoption of generative AI applications in production environments.